Project Report
Wei Chen (wc3@andrew.cmu.edu), Ran You (rany2@andrew.cmu.edu)
December 09, 2021
Summary
We implemented a parallel version of Chess with Multiverse Time Travel using OpenMP and MPI. The parallelization of this game involves two parts, the first is parallelization over multiple boards which evolve together, the second is parallelization of Minimax algorithm and Alpha-Beta pruning, which are used to find the best move on each board at each time step. We measured the performance of our algorithms on GHC machines. Our program achieved a speedup of 2 using 4 cores with the OpenMp and up to 4 times using 8 cores with MPI.
Contents
1 Background
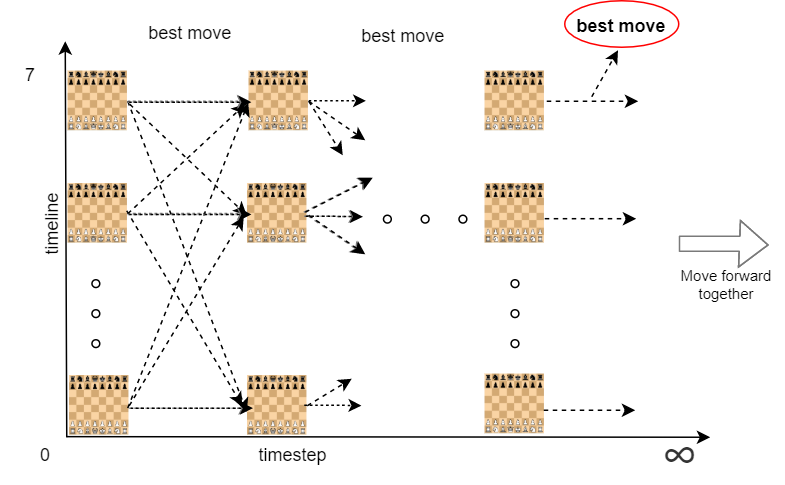
Chess with Multiverse Time Travel is a chess game that allows pieces to travel through timelines or travel back in time, upon which a new board will be created. At each turn, a move must be played on all of the active boards. And the game ends when checkmate happens on any single chess board.
In our project, we simplified the problem by initializing 8 boards, and requiring that pieces can only travel across boards, but not back in time. The rules that dictate how pieces move are the same as in traditional chess, except that now chess boards together form a 3D space, and pieces can move across boards. We simplified the optimization goal by defining the score of the chess as the maximum score of all boards, where the score of each board can be evaluated as in a normal chess program. We also don’t define an end state, we simply repeat the timesteps many times to measure performance regardless of whether the quality of the moves.
The game evolves as follows, 8 chess boards are initialized at the beginning of the game. At each timestep, white and black each move one piece from all of the 8 boards, the move to take is found using monte carlo tree search algorithms (Minimax, or Alpha-Beta pruning).
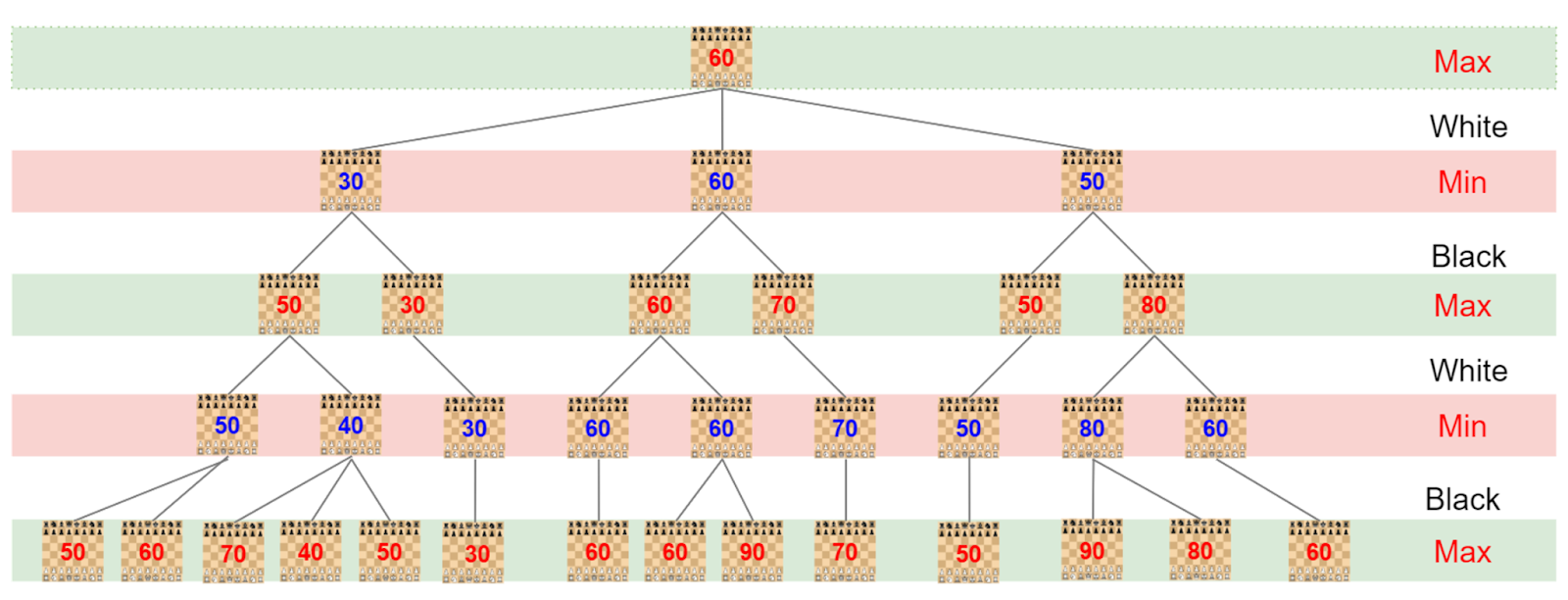
Minimax algorithm is often used in games and programs where two parties compete, such as chess. The algorithm is a zero-sum algorithm, that is, one player chooses the option that maximizes its advantage among the available moves, and the other player chooses the method that minimizes the opponent’s advantage. The Minimax algorithm builds a search tree by simulating moves from both players and evaluate the game states at the leaves, it then simulates the way players make decisions by taking maximum and minimum interchangeably, it finally finds the best move at the root.
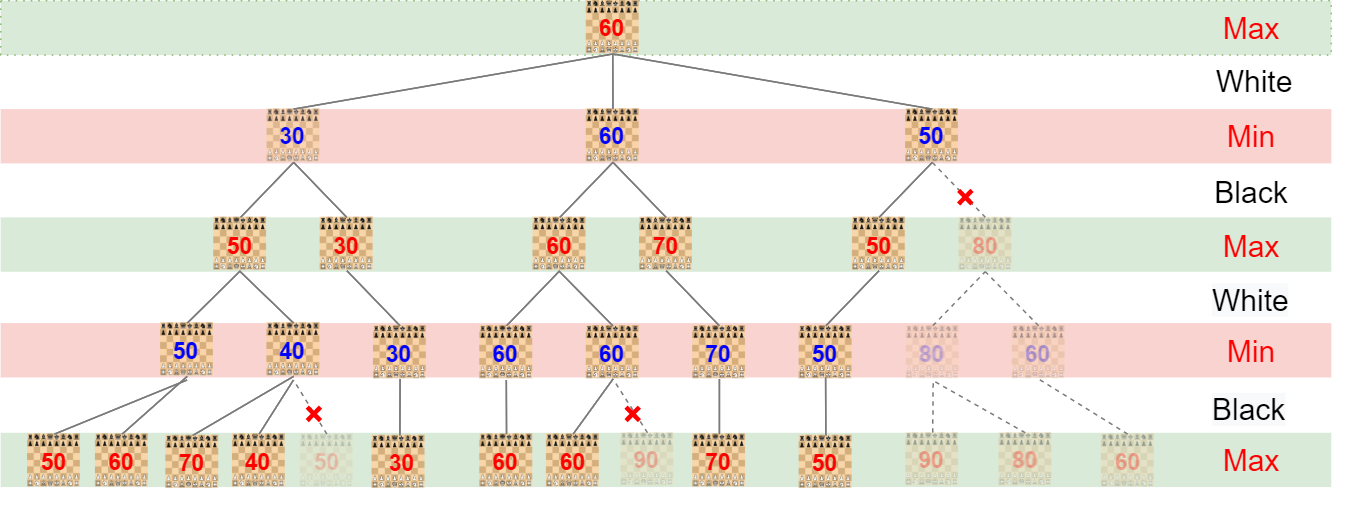
Alpha-Beta pruning is an optimization of the Minimax algorithm. It prunes the branches of the search tree by keeping track of upper and lower bounds of previously evaluated moves (alpha and beta). When the algorithm dictates that no better move can be found according to alpha and beta, it will stop searching that branch. This algorithm finds the same results as the Minimax algorithm, but can prune the tree very aggressively if nodes are well ordered.
Data Structures and Algorithms
Struct Move:
Src position: (int piece, int index, int rank, int file)
Dst position: (int piece, int index, int rank, int file)
class Board:
Data:
int board_index = 0;
int board[BOARD_SIZE][BOARD_SIZE];
Operations:
get_move(int src_rank, int src_file, int dst_rank, int dst_file);
get_color(int rank, int file);
get_piece(int rank, int file);
set_piece(int rank, int file, int piece);
move_piece(Move m);
undo_piece(Move m);
generate_moves(int color);
evaluate_board(int color);
class Chess:
Data:
Board *boards[BOARD_SIZE];
Operations:
Board *get_board(int index);
move_piece(Move m);
undo_piece(Move m);
generate_moves(int index, int color);
evaluate_boards(int color);
function simulate:
Initialize chess
For each timestep {
// white moves
For each board {
best_move = minimax(chess, white)
chess.move(best_move)
}
// black moves
For each board {
best_move = minimax(chess, black)
chess.move(best_move)
}
}
2 Approach
We parallelized the game using OpenMP and MPI. These two frameworks use different memory models, i.e. shared address space and message passing. Since our specific application (Chess with Multiverse Time Travel) involves many levels of parallelization, data sharing, and synchronization, it’s not obvious which approach is more advantageous. We will implement using both APIs, and compare their implementations and performance on GHC machines.
An analysis of algorithms and data structures:
- Level 1:
simulate- The searches are conducted at the same time on all 8 boards
- After each time step, changes to boards must be shared or communicated
- Level 2:
minimax/alphabeta- This procedure builds search trees of some given width and depth, which must be large enough in order to search good results, which is very computationally expensive.
- The time complexity of the Minimax algorithm is O(W^D) and the space complexity is O(WxD), where W is the maximum number of moves generated and searched at each node, and D is the maximum depth of the search tree.
- The actual complexity of Alpha-Beta algorithm can be much smaller due to the effect of pruning, depending on specific problems. We expect Alpha-Beta algorithm to have good pruning capabilities, since in our problem, nodes that are in the same subtree originate from the same move, they should generate similar board evaluation results, which has good data locality.
- When parallelizing the Alpha-Beta pruning algorithms, the pruning capability is reduced because different processors/threads are searching at the same time. This effect can be reduced by communicating alpha/beta during parallelization.
- Level 3:
generate_moves- This is conducted over all pieces on any chess board, and accesses data from 8 chess boards.evaluate_board- This is conducted over all pieces on all chess boards.
Based on the above analysis, these computationally expensive operations are opportunities of parallelization. Since the high level operations are substeps of the lower level operations, and higher level operations share data and game states (better data locality), the lower level should be parallelized first.
The Level 1 operations are intrinsically parallel. The challenge is that at each time step, different processes/threads need to synchronize and communicate moves. Another challenge is that, if given more cores (more than 8 cores), parallelization extends to lower level (Level 2), and thus work distribution and data sharing/communication need to be explicitly managed.
In the MCTS algorithms (minimax and alpha-beta), searching can be parallelized up to some depth (par_depth), below that depth, all operations are sequential. We define three parameters, i.e. max_width and max_depth, which control the size of the search tree, and par_depth, which controls the granularity of parallelization. In order to preserve the good pruning quality of the alpha-beta algorithm, processes need to communicate alpha/beta during searches.
The Level 3 operations are over 8x8 arrays, which can be further parallelized using either SIMD or CUDA, which we did not explore in our project.
Since there are up to 8 cores on GHC machines, and in order to separate effects of different parts of the game, we conducted separate experiments on parallel minimax, parallel alpha-beta pruning, and parallel chess. And finally report results of all parallelization combined together.
2.1 Implementation
We map the problem to target machines based on our previous 3-level analysis. Specifically, we paralized level 1 (chess boards) and level 2 (Minimax algorithm, Alpha-Beta pruning) separately, and then combined them together. We did not parallelize level 3 (move generation and board evaluation). If we have more time, it’d be interesting to explore the effects of parallelization at the last level. Another interesting direction to investigate is combining different frameworks.
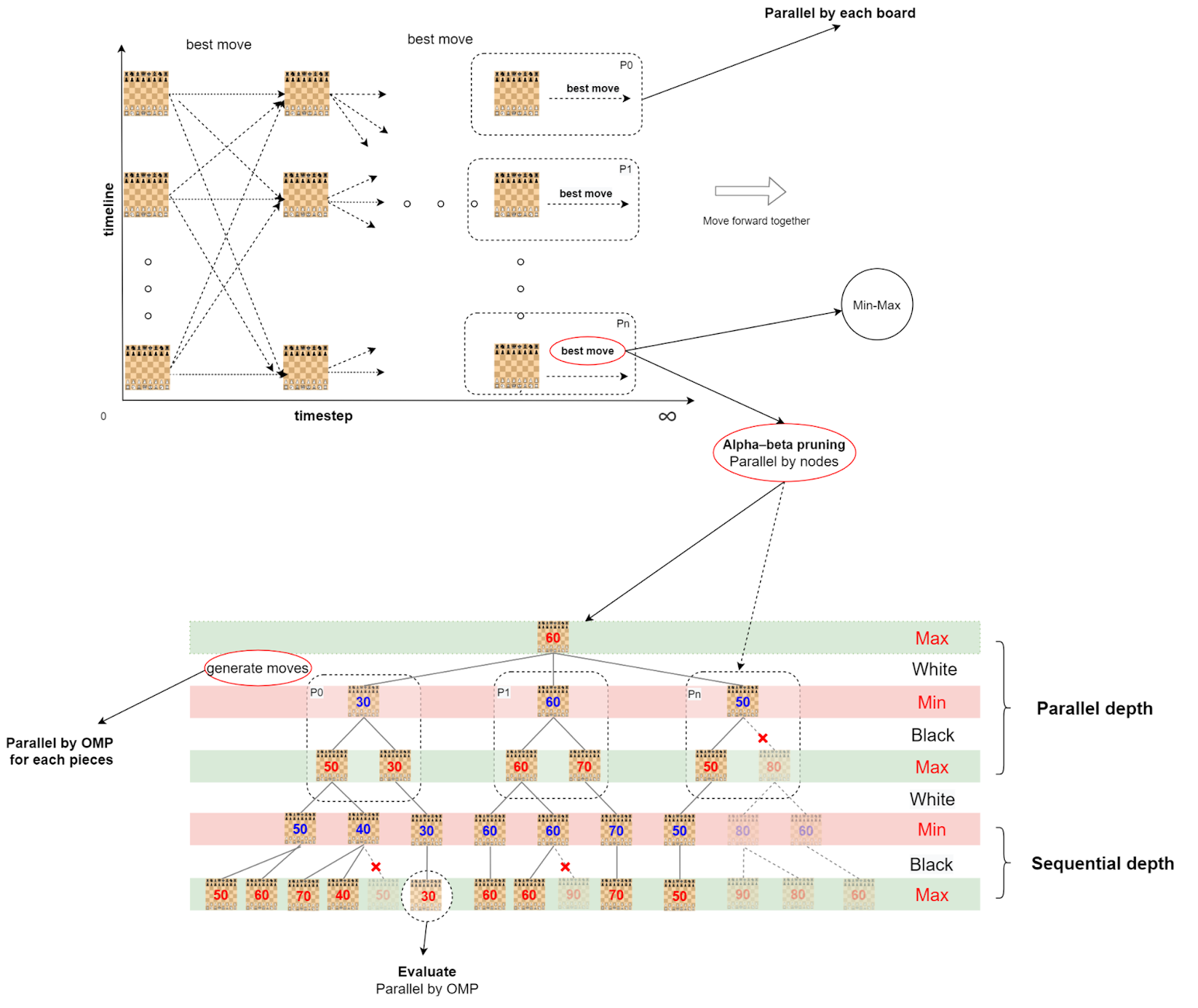
2.2 Parallelization
Level 1: Parallelize Boards
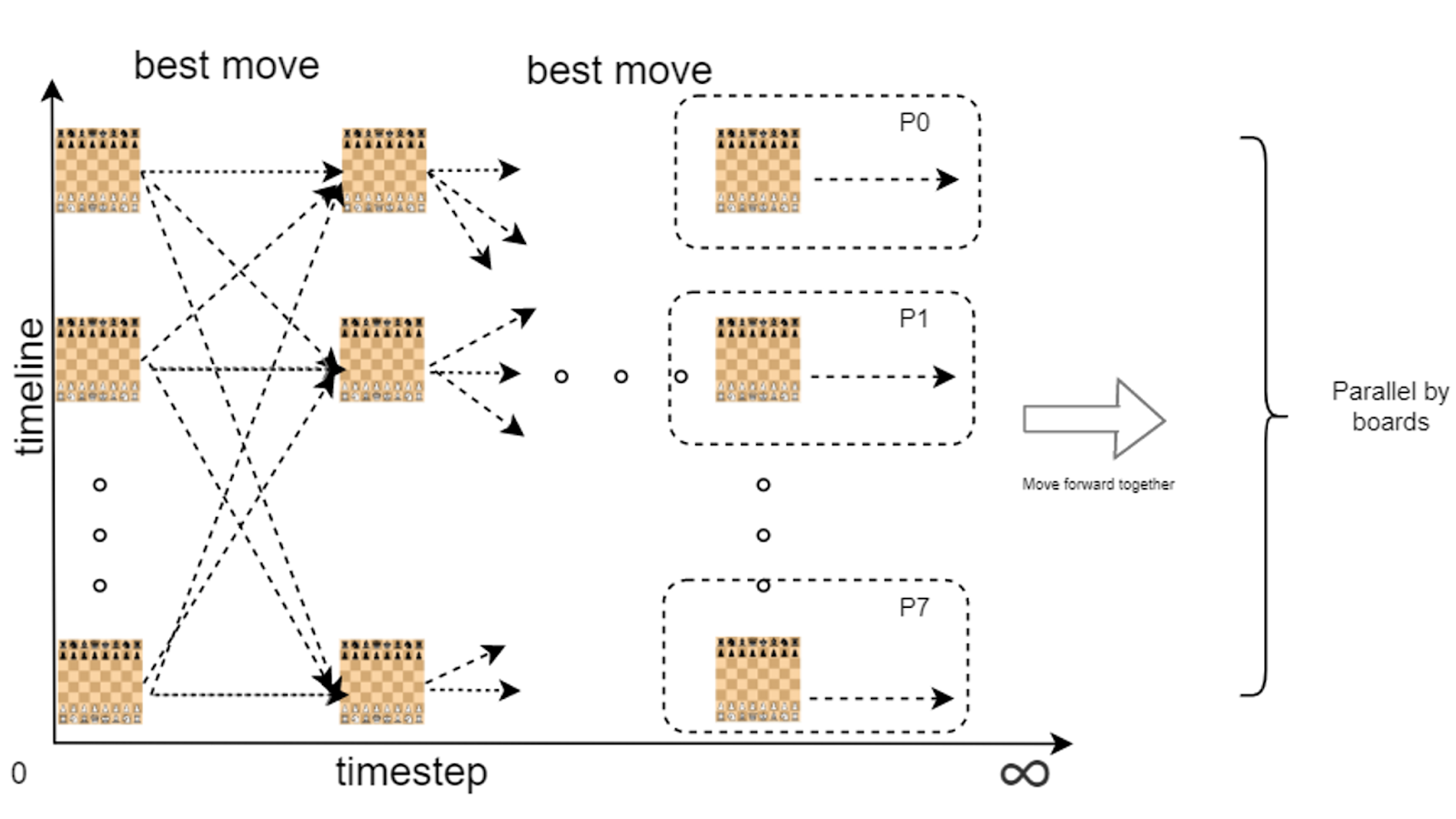
All available resources (processes/threads) are first grouped into 8 groups, each group handles one board. At each timestep, all processes parallelize the work in finding the best move. Then, different groups share/communicate the best moves, and make moves.
- OpenMP:
- Parallelize the 8 chess boards using up to 8 threads, each making a copy of the chess boards before they start finding the best move (which involves modifying chess boards).
- Within each thread, as soon as it finds the best move, it makes the move by modifying shared chess boards, which are protected by locks.
- This is different from the sequential version since 8 chess boards are searched at the same time and updated asynchronously, a thread may or may not see the results from other boards within each time step.
- MPI:
- Map 8 chess boards evenly to processors.
- The root process first broadcasts current chess boards to all processes.
- Each process then finds best moves for boards of its responsibility.
- After searching for the best moves, each process broadcasts the best move to all other processes.
- Within each process, it then updates boards according to the received best moves.
Level 2: Parallelize Minimax algorithm/Alpha-Beta pruning
We define three parameters, i.e. max_width and max_depth that controls that branching factor and depth of the search tree, and par_depth, which controls the depth of parallelization (only in OpenMP).
The deeper the parallelization depth, the more communication and memory overhead, but better granularity, thus better load balancing.
- OpenMP:
- Starting from the root, schedule work by distributing children nodes to available threads. This is done by the omp parallel for dynamic pragma.
- Within each thread, it first makes a copy of chess boards, and modifies boards according to assigned moves, then generates moves and continues scheduling work dynamically, up until the predefined parallel depth, below which operations become sequential.
- The alpha/beta values of children threads at the same level are shared. Usually, there are many more nodes than the total number of processors, as soon as any thread finishes searching any child, it updates the alpha/beta values, which are protected by locks, so that other threads can use the most up-to-date alpha/beta values for pruning.
- MPI:
- Parallelization is implemented as root splitting, i.e. only work at the root is parallelized by evenly distributing children nodes to available processes.
- The root first broadcasts the chess boards to all other processes, then generate moves, and broadcasts moves to other processes.
- Within each process, it searches for the children it is responsible for, and sends the best moves back to root. The root then aggregates the results and picks the best move.
- In order to leverage the advantage of pruning, as soon as a process finishes searching any one child, it broadcasts the results to all other processes, so that all processes their local values of alpha and beta according to the received the results to facilitate pruning.

2.3 Optimizations
In this section, we documented some previous implementations, the optimizations we’ve made, and how we arrived at our current solution.
1 Levels of parallelization. Originally, we started by parallelizing from the upper level (level 3), i.e. move generation and board evaluation, since they are intrinsically parallel operations over arrays. This approach did not result in speedup, in fact, slowdown, due to overhead of launching new processes or threads, and the work is not large enough. Most importantly, we did not correctly identify the elephants in the room, that our problem is hierarchical, with boards at the first level, and search trees for each board at the second level. Also, data locality is better for work closer to each other in the hierarchy. In order to better leverage data locality and reduce the effects of task overhead, parallelizing from top to bottom is a more sensible approach.
2 Granularity of parallelization. When we were parallelizing the MCTS algorithms (Minimax, Alpha-Beta pruning), we started from the root splitting approach by parallelizing only at the root. This is straightforward and simple in implementation, but does not generate good speedup results. We realized that parallel threads in MPI have very different run times, i.e., poor load balancing. Although this is somewhat improved by dynamic scheduling in OpenMP, the load balancing problem still exist, and one way to solve this is to assign work in better granularity. By introducing the par_depth parameter, the user can control the granularity of parallelization.
3 Communicating alpha/beta in Alpha-Beta pruning. From our experiments, we realized that the effects of pruning in the Alpha-Beta pruning algorithm are significant. In fact, the number of nodes visited by the Alpha-Beta pruning algorithm can be thousands times or even magnitudes fewer than the number of nodes visited by the Minimax algorithm in the same setup. However, this effect is reduced after parallelization, since some child nodes are searched at the same time. We previously did not communicate alpha/beta, which results in more nodes to search, thus longer run time. We updated our algorithms by communicating alpha/beta in both OpenMP and MPI implementations.
4 Reducing memory operations. In parallel Minimax or Alpha-Beta, whenever a new thread is launched to search a child node, the chess boards are copied in order to not conflict with other threads. This creates a lot of memory operations overhead. Since one thread is usually responsible for searching for more than one child, the chess board can be reused.
5 Communicating moves vs. boards. In parallel chess, new game states need to be shared or communicated across processes. In MPI, this can be achieved by either sharing moves or sharing boards. We started by sharing boards, which results in message passing of 8x8x8 between processes. We optimized by sharing moves, although each process conducts duplicate operations by moving pieces on their local boards, the message size is reduced.
6 Load balancing. The Alpha-Beta pruning algorithm has poor load balancing, as observed from the runtime of different threads. This is largely due to the fact that some branches can be pruned while searching, thus some nodes can take much less computation than other nodes, which is unpredictable at work assignment. This effect is minimized by dynamic scheduling In OpenMP, but in the message passing framework, we did not find out a good way of fixing the load balancing problem.
7 Fine-grained lock. After 8 boards have found their respective best moves, they need to modify the game states, thus they need to share or communicate the modified chess boards. In the OpenMP implementation, we originally protected the entire game state using a single lock, which results in high contention when the number of parallel processes increases. We changed the single lock to locks for individual boards, and modification is conducted board by board.
3 Experimental Results
Experiment Setup
We measured the performance of our programs by simulating some timesteps of chess playing on GHC machines, and recorded speedup using different number of threads. For all our experiments, we fixed the parameters used in the Minimax algorithm and Alpha-Beta pruning.
Environent:
- Hardware: GHC machines
- APIs: OpenMP, MPI
Parameters:
| num_steps | max_width | max_depth | par_depth |
|---|---|---|---|
| 5 | 16 | 5 | 0 |
- Number of steps: simulate playing for several steps and average runtime
- Max width: branching factor in the Monte Carlo search tree
- Max depth: maximum depth of the Monte Carlo search tree
- Parallel depth: depth in MC tree until which operations are parallelized
Nodes Visited
| Algorithm | Minimax algorithm | Alpha-Beta pruning |
|---|---|---|
| Number of nodes visited | 1118481 | 5181 |
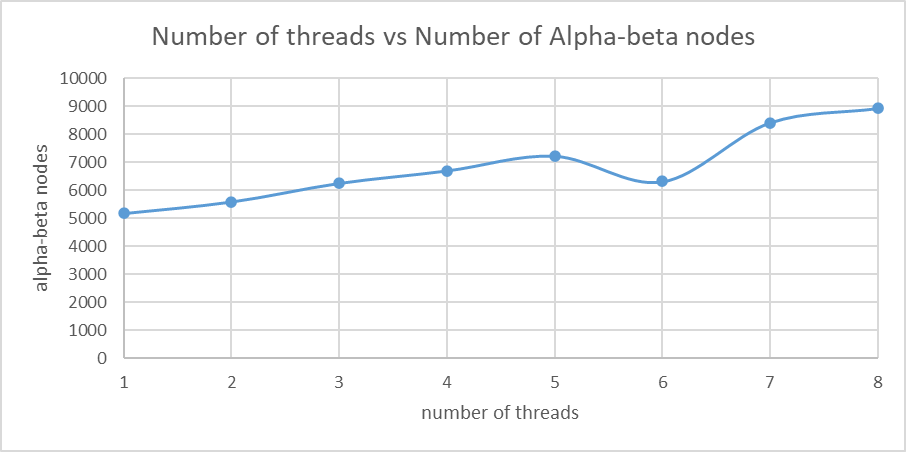
As shown by the above results, the effect of pruning is very significant by Alpha-Beta pruning. In fact, it has reduced the number of nodes visited by about 1000 times. This shows that our application is particularly applicable to the Alpha-Beta pruning algorithm. Also, the number of nodes visited in Alpha-Beta pruning in the parallel version is more than the number of nodes visited in the sequential version, this is as we expected, and we managed to reduce the overhead by communicating alpha and beta values.
Speedup
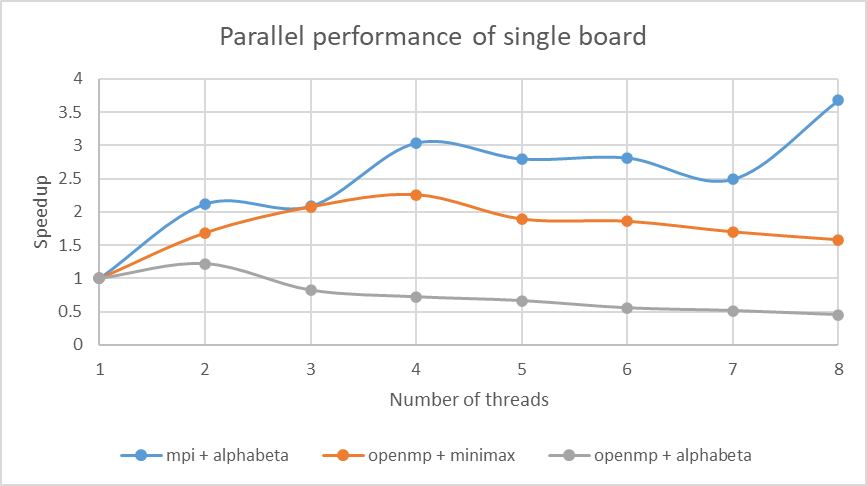

Analysis:
- MPI is slower than OpenMP, but MPI has better speedup
- Parallelization performance of Minimax is better alpha-beta, due to effects of pruning and communication
- Bad speedup due to poor load balancing and synchronization, also many memory allocations and operations to prevent read/write conflicts
- Chess boards speedup is better than single board speedup
Minimax vs. Alpha-Beta
As shown above, our parallel chess programs with Minimax algorithm and Alpha-Beta pruning both achieve best speedup at 4 cores using OpenMP. The speedup of the Minimax algorithm is slightly better than Alpha-Beta pruning, which is expected, since alpha-beta pruning has poorer load balancing.
One reason why we could not achieve ideal speedup is data transfer. In order to leverage the dynamic scheduling of OpenMP, each thread will create new chess boards and copy data from original board, which creates much overhead in memory operations. Another main source of overhead comes from synchronization. There is synchronization at each parallel level of the search tree, and there is synchronization at each timestep of the chess game.
OpenMP vs. MPI
In terms of the exact running time of these implementations, the running time of OpenMP is smaller than the MPI implementation. But the speedup of MPI implementation is better, as demonstrated in the speedup above plot, speedup is still significant up to 8 cores. However, the speedup is much less than the number of cores used.
In terms of message passing, load balancing is the main source of overhead. We directly distribute work to all available resources, and as pointed out previously, alpha-beta pruning can generate very uneven workloads across children nodes, and we did not implement more complicated methods to better balance work loads. Another main problem is synchronization and message passing, synchronization happens after each child node search, after which processes communicate data to update alpha and beta. After all boards complete searching, they synchronize again when exchanging moves information. And synchronization happens again after each timestep. Another main problem of MPI is that it’s very hard to parallelize in multiple levels while maintaining good load balancing.
Future Work:
- Better optimization in OpenMP framework.
- Parallelize move generation and board evaluation using CUDA or SIMD.
- Combining parallelization from different frameworks.
References
- [1] I. Wikimedia Foundation, “Alphabeta pruning,” 19 October 2021. [Online]. Available: https://en.wikipedia.org/wiki/Alphabeta_pruning
- [2] I. Wikimedia Foundation, “minmax,” 5 October 2021. [Online]. Available: https://en.wikipedia.org/wiki/Minimax
- [3] Singhal, Shubhendra Pal, and M. Sridevi. “Comparative study of performance of parallel Alpha Beta Pruning for different architectures.” 2019 IEEE 9th International Conference on Advanced Computing (IACC). IEEE, 2019.
- [4] Strnad, Damjan, and Nikola Guid. “Parallel alpha-beta algorithm on the GPU.” Journal of computing and information technology 19.4 (2011): 269-274.
- [5] Brockington, Mark Gordon. Asynchronous Parallel Garne-Tree Search. Diss. University of Alberta, 1998.
- [6] Hyatt, Robert M., Bruce W. Suter, and Harry L. Nelson. “A parallel alpha/beta tree searching algorithm.” Parallel Computing 10.3 (1989): 299-308.
- [7] Project from previous students: “Chess AI” https://github.com/ihajhasa/Parallel_Chess_AI
- [8] Project from previous students: Nancy Xiao and Jemmin Chang. “Parallel Game Tree Evaluation”. https://jchang504.github.io/projects/418project.html
- [9] Chess in 5D (open source): https://chessin5d.net/